maths Given a Hidden Markov Model with known parameters (stationary distribution/ transition probability/ emission probability) we can calculate the likelihood of seeing a sequence observations, efficiently using the forward algorithm.
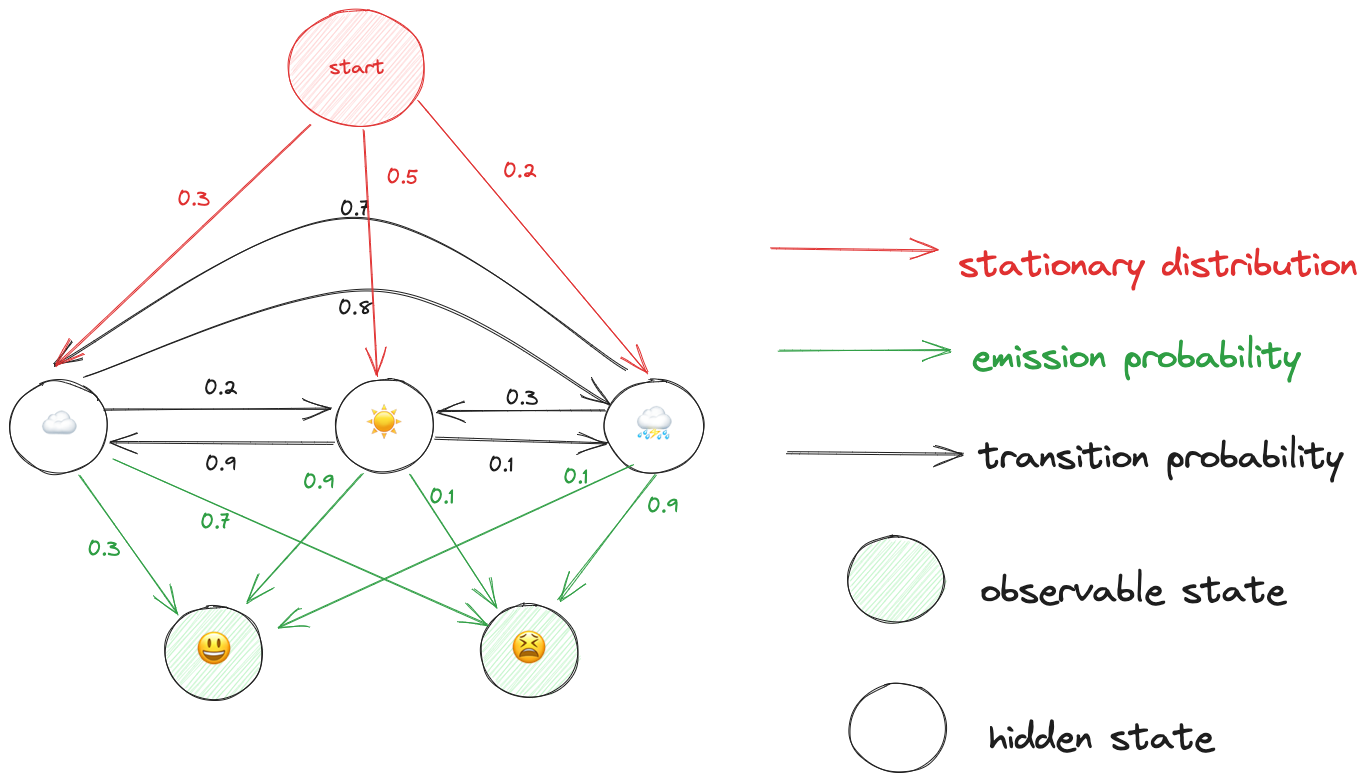
Let’s say we observe 😫,😃. What is the likelihood of observing these states, given our hidden markov model?
The naive approach is to enumerate all possible hidden states and sum their probabilities. That is:
Where:
- represents a sequence of states through the HMM that generates the observations .
- is the probability of observing the sequence given the state sequence , which is the product of the observation probabilities for each observed symbol at each step in the sequence given the state at that step: .
- is the probability of the state sequence , which includes the initial state probability and the product of the transition probabilities for each transition in the sequence: .
- The sum is taken over all possible sequences of states of length .
We can expand the equation to:
For the permutations of states that can give rise to are
The number of possible hidden states can be calculated with:
where is the number of states and is the number of observations. This is an exponential function that grows with the number of observations we make.
The probability of making observation is:
Writing it out we can see that we are recomputing certain parts of the equation. For example is computed 3 times. We can make the computation of much more efficient by computing it recursively. This is where the forward algorithm comes in.
Let’s recompute our example using the forward algorithm:
The complexity to compute the forward algorithm is . This is because for each of the observations , we compute the transition from each state to every other state leading to .
In comparison the complexity for the naive approach is , which is infeasible for even moderate sized .
Further Reading: